SMI 一种全新的遗忘审计策略,简单高效且有统计价值
Too Long, Don't Read:
在本篇博客中我们将定义遗忘审计问题,并提出什么是好的遗忘审计指标,并介绍我们设置的一种遗忘审计指标:SMI。简单来说它是把审计问题通过启发式的思想修改为了混合比例估计问题。审计问题是复杂的,但混合比例估计问题事实上是非常简单的。
1.引言
所有做Unlearning的人可能都会遇到一个鲜明的问题:我们如何去判断自己训练的这个模型是否成功实现了遗忘?大模型内部其实存在很多方法我们暂且不去讨论,我们目前只讨论一个纯粹的CV问题。不难发现现有的研究都存在一堆问题:
- 遗忘审计是一个存在歧义的审计,我们不知道这个审计方法本身是否可靠。
- 遗忘审计需要的成本太高了,如果是MIA类审计那么影子模型完全是无法接受的开销。
- 一个好的指标最好是随着round去打印的,这样能指导我们的训练过程,但目前大部分的遗忘审计都做不到这一点。
OK,在介绍我们的工作之前,我们发现近期在ICLR上的一篇相关工作事实上已经解决了其中的后两点问题,这是和我们的同期工作。可惜的是我们没有看ICLR在完全录用前论文的习惯,故我们论文在2025年10月进行SMI的相关工作时没有注意到这篇文章,如果我们更早的注意到这篇文章它的思想能够很好的对我们的工作进行进一步的改良,这篇文章和我们有相同的出发点,类似的结果,支持在阅读我的Blog前一读,我们也在最新版的论文去引用了这篇文章。
最新的他人工作论文,值得一读的有趣文章:基于子集统计独立性的机器遗忘评估
我们的工作:一种混合比例估计的遗忘审计策略
话说回来,那么传统的unlearning审计策略是什么呢?其实最经典的一种就是MIA成员推理攻击了:它的核心观点是把数据集分成两种Member与Non-member数据,通过一个二分类器对它进行判别是否参与过模型训练之中来完成审计。其中它会使用神经网络对这些数据推理得到的特征来进行审计。一个经典的策略是训练过的数据它的神经元梯度较小,没训练过的数据神经元梯度较大。故我直接把它们的神经元梯度都打印出来,做一个二分类就知道它有没有被训练过了。
除此之外的背景补充就是,因为MIA是安全领域的内容,故在以前的MIA讨论的重点一般都被放在,如果我不能访问这个模型,我如何做判别呢?若你感兴趣这部分内容可以看安全四大的RuLI,在这里我不做过多赘述。你只需要知道一个核心结论就是,传统对MIA的改良一般是建立在一个较为苛刻的假设下,模型参数不能被访问,即黑盒MIA。为此相应的影子攻击改良也是针对于这些,反而在白盒的MIA下没有做出更多好的工作。因为大部分的安全研究者认为只提出一个白盒的MIA是价值不大的。
很容易理解啊,所以说现在的问题就是,如何在白盒上做好审计工作其实是一个很大的空白,那么什么才是一个好的审计指标呢?
2.一个优秀的评价指标要满足的性质
一个优秀的评价指标,它至少要满足以下几个性质:
- 1.稳定。
- 2.高效。
- 3.有信息价值。
先说稳定。从传统的评价指标,例如ACC这个指标来看,它最大的特点就是有一个固定的输入,输出。ACC本身只是一个无情的函数计算器,它和别的东西都没有关系。你不需要考虑一个问题:目前ACC是否合理?如果ACC不合理(我是杠精,我就要讨论长尾问题和二分类异常分布),那么我相信真阳假阳,真阴假阴这一套和ACC相匹配的指标也可以解决你的问题。严格来讲稳定的定义就是:我在使用这个评价指标的过程中不需要去思考这个评价指标是否是正确的。
那么MIA为什么不稳定?因为MIA的所有过程都可以理解为训练或选择一个二分类器,那么你在对MIA审计的过程中不可避免的就要考虑到一个问题:MIA它这个二分类器训练的效果到底好不好?你在使用一个基于MIA得到的指标前,你需要用ACC这套指标去判断目前这个MIA指标是否合理。在这个过程中引入了一个极强的人类先验。并且也存在一个问题:如果MIA训练得到的结果不合理那么我怎么办?我重训一个MIA还是直接更换方法呢?我们接下来会讨论这个先验,在有信息价值里去讨论。
高效,很好理解,就是计算开销小,计算快。我做完推理直接就做完审计就是最好的。就像ACC
有信息价值:我们不得否认,遗忘审计不存在一个像真阴真阳,假阴假阳这样公正的评价指标,那么我们必不可免的引入人为的先验。那么有信息价值的时候我们必须要考虑一个问题,这个先验到底合理不合理,如果合理能告诉我有多合理吗?如果不合理能告诉我有多不合理吗?
OK,那么我们不难得到以下结论,一个好的unlearning审计策略需要做到:不需要动脑,即插即用的稳定;像我一样做理论的穷逼也可以使用的高效计算;还有我用的时候一看结论就知道它是否合理的审计指标。
好消息好消息,如果你不喜欢我们的论文,那么你也可以去用基于子集统计独立性的机器遗忘评估的结果,这个也实现了以上几个内容。
接下来要开始忽悠你接受我们的方法SMI了,那么接下来是大忽悠时间。
3.SMI,我2025年最喜欢的遗忘审计工具
那么我们重新思考遗忘工作到底在做什么:现在我有一个模型参数$w$,我希望去遗忘一组样本$X$,那么我希望从第一次迭代开始,这个$X$就对模型参数$w$没有任何梯度贡献。但是你唱一百遍的反方向的钟也回不到过去,事实上这个过程是难以实现的。
那么我们就构造了一个遗忘了$X$的模型参数$w’$你就当它是平行世界训出来和$X$无关的一个模型参数,那么很直观的一个思路就是,我让$w$和$w’$无比接近就好了?这不是一个很好的审计策略吗。
如果你觉得这个暴论合理,说明你应该回去补习凸优化了,首先神经网络是非凸的,哪怕很接近也不说明它俩的性能接近,你如果说是用L-smooth光滑概括住,你知道这个L多大吗?,其次最重要的你如果能拿到这个$w’$,你不就实现了完美的遗忘吗,还审计干嘛?
OK,这个讨论得到了一个悲观的现实:任何从模型参数出发的审计策略,在你没有解开神经网络这个黑盒时,都是在胡言乱语。
很自然的,我们要考虑一种使用样本策略来审计的方法,那么在这里我们遵循传统MIA的一个假设(我也想不遵循啊,不遵循就完全没办法审计了)。审计遗忘数据集的本质是让它和测试集的表现非常接近。那么我们不加证明的给出一个十分过分的暴论,我们能不能假设遗忘数据集的特征分布,是训练集的特征分布和测试集的特征分布的混合?
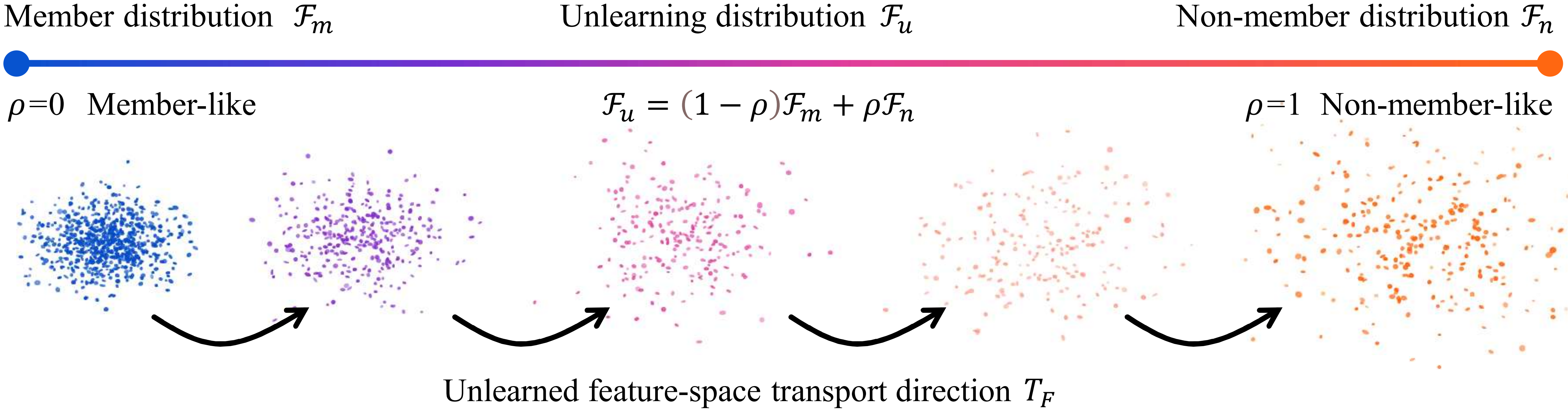
我们假设被遗忘数据是训练数据和测试数据的一个混合。
如果你接受这个假设的话,那么我们做审计的过程就非常简单了,直接估计这个混合比例是多少就可以了!那么所有问题都转化为对$\rho$的求解,对$\rho$的求解是无监督领域里面的经典问题,在这里不做过多赘述,你可以直接看原文。事实上直接用协方差或核距离嵌入就可以做简单的求解了。(PS:我发现了一篇2016年的JMLR居然把这个问题做的特别好,这下是前人栽树后人乘凉了。)
4.效果如何?
效果在重训练上真的Niceeee!它是我在完全重训练上最鲁棒的一个审计策略,别的审计策略会因为各种超参数导致结果,事实上如果你用核距离嵌入只需要用高斯核加中位数方差就可以做到最好的结论了,完全不需要选任何核!
5.对假设的讨论
其实你可以看到,这篇论文的思想非常简单,如果你接受了对$\rho$的求解,那么事实上这篇论文就退化成了一个本科级别的最优化任务,那么问题就是这篇论文为什么相信$\rho$求解是可信的呢?为什么我们的方法能有稳定,高效,提供信息的优点呢?
对$\rho$的求解可以假设为我们构造了一个线性回归模型,我们只是构造了一个带约束的线性回归方程。那么我们很高兴的就是,我们完全可以去通过对线性回归方程的基本评价指标来评价SMI方法。那么我们可以算残差,我们发现在正常遗忘的所有情况下残差都保证了较小的结果,这说明在高维空间中,这些特征其实呈现了一种诡异的线性结构。这和目前大量对一些线性表现特征是相匹配的。
其次,我们的审计过程哪怕失效也很明显,因为我们构造的是软约束$\rho$。一旦你发现混合比例中出现$\rho>1,\,or \, \rho<0$的情况就知道本次审计失败了。我们也尝试考察了这种情况,我们发现构造一种基于对抗攻击的虚假遗忘能够出现$\rho»10$的情况,这甚至是一种较弱的防御审计策略。这也很NICE。
除此之外呢,我们可以对遗忘数据集在计算$\rho$时对$\rho$进行重抽样,去考察遗忘特征本身的稳健性程度,我发现如果你的遗忘是稳定的,那么重抽样过程不会超过20%的偏差。事实上这和MIA相比已经是远超于它的稳定性了。
最后就是,如果你采用了这个方法进行审计,那么你要注意,所有基于分布进行计算的内容,它的计算误差的方差都一定会和样本量有关。我们的研究工作也讨论了这一点,它至少每一类要有20个样本才能保证稳定。
6.一个重要的Insight:我们放弃了Wasserstein 距离
事实上我们经常认为Wasserstein 距离是一个很好的东西,GAN也用,神神秘秘的自适应策略也用,LLM也用。好像Wasserstein 的缺点只有计算速度慢这一个令人悲伤的问题。
我们也是俗人,我们一开始认为使用Wasserstein 来设计SMI一定是全世界最好的SMI,实验结果却狠狠地打了我们的脸。我们发现Wasserstein 的效果奇差。但原因其实很简单。
Wassterien是检测分布迁移的策略,它根本不适用大部分的机器学习方法!以Wasserstein 来审计训练集和测试集的特征为例,用Wasserstein 测量出来的结果可以被看作是这两个数据集的特征迁移过程,如果我们测量两个数据集的路,可能很长。但是它们的迁移过程可能很短!一个最简单的例子就是,如果两个人相隔一百米,一个人跑得快,一个人跑得慢。那么它们的迁移过程就是跑的快的跑60m,跑得慢的跑40m。这和测量他们两个的真实距离是完全不一样的!这一个现象也警示了我们,不能因为Wasserstein 是一个测量分布度量的好方法就胡乱使用!
7. 尾声
因本人事情较多,最佳可能更新很多Blog,这个Blog写的较快,较乱。更具体的内容可参照原文,如感兴趣,我期待和您的继续交流与更新。
Enjoy Reading This Article?
Here are some more articles you might like to read next: