深度学习里的流形优化 I——尺度不变性的历史
Too Long, Don't Read:
在本篇博客中我们将讨论流形优化的相关内容,从孙剑老师的球面动力学开始,在这里对这位学者致以最高的敬意。
1.引言
在近期的工作之中,我发现许多人对流形优化的相关工作兴致很高,特别是Muon,Muon-H,MOGA,RMNP。此类工作在社区中引发了极大的关注并且推动了流形优化在优化器领域中的讨论,其中在国内中对此推动最大的无疑是苏剑林和温凯越两位优秀的研究者。但我们必须注意到一个严峻的问题。
他们的博客写的太好了,导致许多人对流行优化的根本动机并不够清楚。
我注意到特别是苏剑林老师的博客存在部分省略工作,这对于一个博客其实是很正常的,我个人的博客也经常省略许多东西。但是苏老师目前在国内的影响力之高,导致许多人会优先阅读苏老师的博客作为基础动机的启发而放弃去阅读一些陈旧的文献,我认为这本质上是对后续研究中存在部分误解的。
除此之外,对于Muon的相关工作,包括为什么正交化能够提高模型性能;与行归一化作为正交化的一种近似为什么能起到良好的效果都是值得进一步探究的。这是一个宏大的愿景,我会试图用这几年时间去同步探索流形优化的真正原因。
本博客将从球面动力学的第一篇论文中出发,事实上这些内容与Kaiyue的博客有很多重复,我个人建议阅读本博客后再阅读Kaiyue的博客权重衰减的部分探究。
最后,向球面动力学论文的相关作者致敬,格外强调的是作者之一孙剑老师是我在人工智能领域的引路人中的一位,虽然我们仅有寥寥数次的交流,但他对我的影响是极其深远的:Spherical Motion Dynamics: Learning Dynamics of Neural Network with Normalization, Weight Decay, and SGD。
2.有效学习率是什么
在这里我们要先讨论一个简单的优化问题。对于一个最优化问题而言,我们一般考虑一个一阶优化的收敛存在三种表达式(在这里提一嘴,这三点是不完全等价的,但我们不会讨论这个事情。 ):
迭代自变量(模型参数)的完全拟合: \(\|w_T-w^* \|\le \epsilon\) 迭代因变量(模型输出)的完全拟合: \(\|f(w_T)-f(w^*) \|\le \epsilon\) 一阶导为0的同时保证这一点为极小值点: \(\|\nabla f(w_T)\|\le \epsilon\) 在早期,我们一般认为第三种是一个良好的拟合表现,这时有一种名为平衡状态的观点被提出,即在两步迭代中更新量已经足够小即为模型已经收敛了,具体表达为:$w^t \approx w^{t+1}$ 。这是一种极其自然可靠的猜想,因为此时的模型更新量往往被看作足够小的状态,所以此时更新较小。当然,为了更加严格(尽管如此它在数学上依然很不严格),我们对这种观点定义为平衡状态,同时采用参数的范数去定义 $|w^t|_2 \approx |w^{t+1}|_2$ 去定义模型参数范数的平稳状态。
但是其实这部分内容依然存在着一个歧义,就是这种直观的结论是否合理且可靠呢?理论工作者在神经网络中最重要的一个工作就是根据理论的相关启发式观点和实践建立起联系,并进一步指导实验。
我们先考虑现代网络的结构,一个很重要的现象是尺度不变性:即对于带有归一化层的神经网络,存在现象为:$f(x\vert w)=f(x\vert kw)$ 。 即模型参数如果扩大 $k$ 倍,模型的输出也还会相同,这是归一化层带来的约束作用。
那么我们对这两边求导会发生什么呢?
\[\nabla f(x|w)=k\nabla f(x|kw)\] \[\frac{\nabla f(x|w)}{k}=\nabla f(x|kw)\]非常直观的结论就是较大的模型参数会导致模型的梯度变小!这导致在模型更新的过程中,存在一个这样的动力学过程模型范数变大了,最后导致实际的更新变小了。为此我们提出一种启发式的学习率来判断模型的更新状况,即有效学习率:$\eta_{eff}=\frac{\eta}{|w|^2_2}$ 。通过观察有效学习率的大小来判断模型更新的动态过程。
OK,这是一个直觉易于接受的结果,然而我们很激动地发现 $\eta_{eff}$ 背后存在着一个深刻的几何原理,即 $\eta_{eff}$ 本质上是单位球面上的SGD学习率。我们对这个内容按照原论文的思路进行复制式证明。
Defintion 1(单位梯度). 若$w_t\neq 0$,定义归一化梯度 $\tilde{w_t}=\frac{w_t}{|w_t|^2_2}$ ,则我们定义 $\frac{ \partial \mathcal L}{\partial w}\vert _{w=\tilde{w_t}}$ 是 $\frac{ \partial \mathcal L}{\partial w}\vert _{w=w_t}$ 的单位梯度。并且在尺度不变性的语境下,显然存在:
\[\frac{ \partial \mathcal L}{\partial w}|_{w=w_t}=\frac{1}{\|w_t\|_2}\frac{ \partial \mathcal L}{\partial w}|_{w=\tilde{w_t}}\]带入到SGD的更新规则中,可以写更新过程为:
\[w_{t+1}=w_{t}-\eta\frac{ \partial \mathcal L}{\partial w}|_{w=w_t}\]当平衡态成立的时候 $|w_t |2\approx|w{t+1} |$ ,两边同时除以 $|w_t |_2$ 可以得到:
\[\tilde{w}_{t+1}=\tilde{w}_t-\frac{\eta}{\|w_t \|^2_2}\frac{ \partial \mathcal L}{\partial w}|_{w=\tilde{w_t}}=\tilde{w}_t-\eta_{eff}\frac{ \partial \mathcal L}{\partial w}|_{w=\tilde{w_t}}\]证毕,根据上式可直接得到结论, $\eta_{eff}$ 本质上是将模型参数归一化到单位球面上的SGD有效学习率。因为平衡状态成立,所以我们认为两次更新过程中本质上是在单位球面上进行的更新,即从球面上的一点走到了另外一点。但由于单位梯度未知,所以无法仅通过 $\eta_{eff}$ 判断此次更新的具体幅度。
Remark 1:在这里提供一个与本博客无关的视角,从工程上来看大部分的基于球面动力学的优化器一般是在训练末期阶段突然出现的Loss下降导致性能提升,这里一个启发式的观点是模型在早期并没有进入平衡状态,故更新本质上是在膨胀的球面或一个缩小的球面上做更新。只有当权重参数较为稳定的情况下,才可以把两步更新看作球面上的更新。当然我们也可以看到有人对此提出了硬性约束来保证球面更新符合动态,这也是一个有价值的视角。
3.有效学习率的不足之处与角度更新量
因为单位权重是和超参无关的内容,难以直接分析它的更新量大小,故我们结合球面动力学提出一个观点:它既然在球面上运动,那么它的更新能否用角度去衡量?为此提出一种基于角度更新的定义:
Defintion 2(角度更新). 假设 $w_t$ 是神经网络中的尺度不变权重,则定义角度更新 $\Delta_t$ 为:
\[\Delta_t =\angle(w_t,w_{t+1})=arcos(\frac{\langle w_t,w_{t+1}\rangle}{\|w_t \|\|w_t+1 \|})\]因梯度和模型参数垂直的性质,我们不妨假设在一个很小的学习率下存在:
\[\Delta_t\approx \tan(\Delta_t)=\frac{\eta}{\|w_t\|}\|\frac{ \partial \mathcal L}{\partial w}|_{w=w_t}\|_2\]从这个式子我们不难直接得到一个结论:在去除其他变量的情况下,更新量事实上和模型权重范数成反比,而和梯度成正比关系。这代表着标准SGD更新过程会不断放大权重范数和缩减梯度范数。这相对于单位梯度提供了更加坚实的一个想法,模型更新的停止不是因为收敛,而是由于模型范数太大了导致角度更新太小了。
而模型参数在更新过程中被放大可以被直接证明:
\[\|w_{t+1} \|_2^2=\|w_t \|_2^2+(\eta \|\frac{ \partial \mathcal L}{\partial w}|_{w=w_t}\|_2)^2>\|w_t \|_2^2\]那么在这一段讨论中,我们讨论了一个重要的动力学观点:更新的过程中存在因模型权重范数不断变大而导致更新量逐渐减小,而且这可能导致在不断地更新过程中,模型还没有收敛但有效更新已经变得很小了。
解决方案是什么?那么我们考虑更新过程:
\[w_{t+1}=w_{t}-\eta\frac{ \partial \mathcal L}{\partial w}|_{w=w_t}\]如果我们能将更新过程中增加一个与梯度无关的衰减项,就可以有效控制模型范数增加而导致的有效学习能力下降现象,一种方法是权重衰减。
4.权重衰减带来的结果
考虑一个简单的SGD下的权重衰减:
\[w_{t+1}=w_{t}-\eta(\frac{ \partial \mathcal L}{\partial w}|_{w=w_t}+\lambda w_t)\]基于此推导 $w_{t+1}$ 的范数更新为:
\[\|w_{t+1} \|_2=\|w_t \|_2+\frac{(\eta \|\frac{ \partial \mathcal L}{\partial w}|_{w=\tilde w_t}\|_2)^2}{2\|w_t \|^3_2 }-\eta \lambda \|w_t \|_2\]显然权重衰减在更新过程中不断减小模型范数。在这里我们不妨假设单位梯度是固定不变的,那么当权重衰减和梯度更新项两者分别与模型参数成正比和反比,这一个过程可以看作球面上的圆周运动,模型参数在不断朝向圆周运动稳定的情况下进行迭代(如图1所示)。
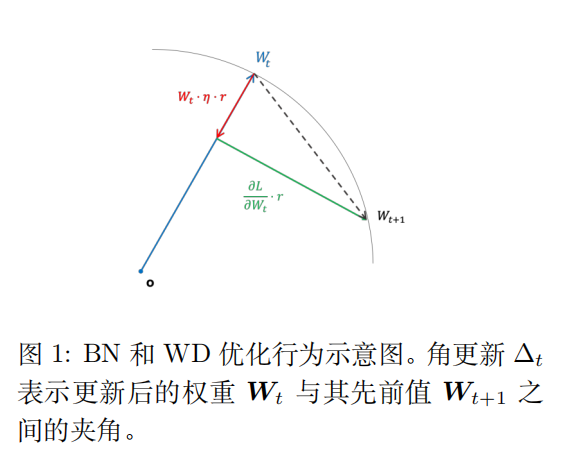
从论文中的截图。
直观的来讲,梯度负责更新模型在球面上的位置,但此次更新会导致模型远离球面,若模型参数远离球面,其落入了一个更大的球面空间中,那么相同的步长下,在半径更大的球面上要走的步数就更多。而权重衰减的意义是将参数一直拉回球面来防止落入到一个膨胀的球面过程。
遗憾的是,这些观点和结论依然是启发式的,我们必然在日后需要一个更加严谨的推导和结论。但是我们要思考的是,当权重衰减的步数更大的情况下,是否会让模型一直收缩到一个$R=0$的球?那么权重衰减和学习率需要不断权衡的过程。那么显然的就是,如果我们增加流形(几何)约束可以做到替代权重衰减的工作,这也侧面的验证了Kaiyue对权重衰减的评价。
那么本Blog遗留了两个问题:
-
权重衰减真的只存在控制模型范数的意义吗?
-
什么样的几何约束可以控制模型范数?
这两个问题代表着日后讨论的内容,事实上权重衰减作为优化器的重要组成部分,它的含义就是为了解耦正则化项,但权重衰减和规范化层一同出现导致的耦合效应是在科研中不断发现的。这也启发了我们,事实上神经网络因为架构复杂,我们提出的模块往往会因为未知的原因而生效,而在这里提供一个我自认为良好的品味就是,如果一个带有超参数的架构它被工程上验证了十分有效,那么对它背后的调参策略进行机理分析是非常必要的。
5.对权重衰减的额外讨论
事实上我们发现,对权重衰减的讨论早已经超越了统计里面对Lasso的讨论,正则化项已经不是为降低模型复杂度这么简单的一个结论。在传统的观点中,正则化项是为了避免模型过拟合,在传统模型较为好求解的情况下这个观点是十分合理的。
神经网络和传统统计模型的最大差异:神经网络是一个难以求解的问题,作为一个统计工作者我不可避免地承认,传统统计的大部分问题实在是太容易求解了,导致对模型动力学的演化过程探讨的并不够深入。在简单统计工具上养成的直觉在神经网络中难以直接复现,一个让我感觉恐怖的事实是,低维概率和低维统计的课程已经不能对AI科研产生任何良好的直觉培养,反而是一个阻碍直觉的过程。
在这里,笔者延续了大胆下结论的风格,我认为目前神经网络的可解释核心在短期内最容易被解决的就是:梯度下降过程的动力学状态。
6.杂谈
我们能看到近期优化器的工作讨论度是近期的一个小高潮,不同的优化器在快速涌现。这是一个合理的历史规律,但我们在这个过程中可能需要更加严谨的进行理论研究和实验,快速发展的周期很容易导致不公平的比较和不可靠的复现。每一个科研者应该胆大心细的去探索相关研究,追求快速的论文我认为并不是优化器工作的风格。
7.致谢
感谢Ruosi Wan, Zhanxing Zhu, Xiangyu Zhang, Jian Sun的球面动力学论文。这是目前优化器流形约束中一个重要的观点根基之一,虽然尺度不变性讨论的论文很多,但我看来这篇论文的影响是要高于一些同期工作的。本篇Blog是基于这篇论文的复制性证明,感谢他们的工作来支持了我水一篇Blog。
感谢xxxx企业对本工作的支持与赞助。(广告位招租)
Enjoy Reading This Article?
Here are some more articles you might like to read next: